
Minerva Architektur
Allgemeines
In diesem Artikel findest du eine klare Übersicht zur Systemarchitektur von Minerva, eine Darstellung der unterstützten KI-Modelle (einschließlich On-Premise- und Drittanbieter-Optionen), die Voraussetzungen für die Integration eines eigenen Modells, einen schrittweisen Einblick in den internen Datenfluss, veranschaulichende Anwendungsfälle zur Verbesserung von Process-Mining-Workflows durch Minerva sowie eine kompakte Zusammenfassung zur EU AI Act-Konformität.
Architektur
Die folgende Grafik zeigt die übergeordnete Architektur unseres KI-Assistenten Minerva, der nahtlos in die Noreja-Plattform integriert ist. Diese Darstellung hilft dir, den Datenfluss im System zu verstehen und wie unsere KI-Funktionen mit deinen Daten interagieren – stets unter Wahrung deiner Datenschutzvorgaben und Kontrolle.
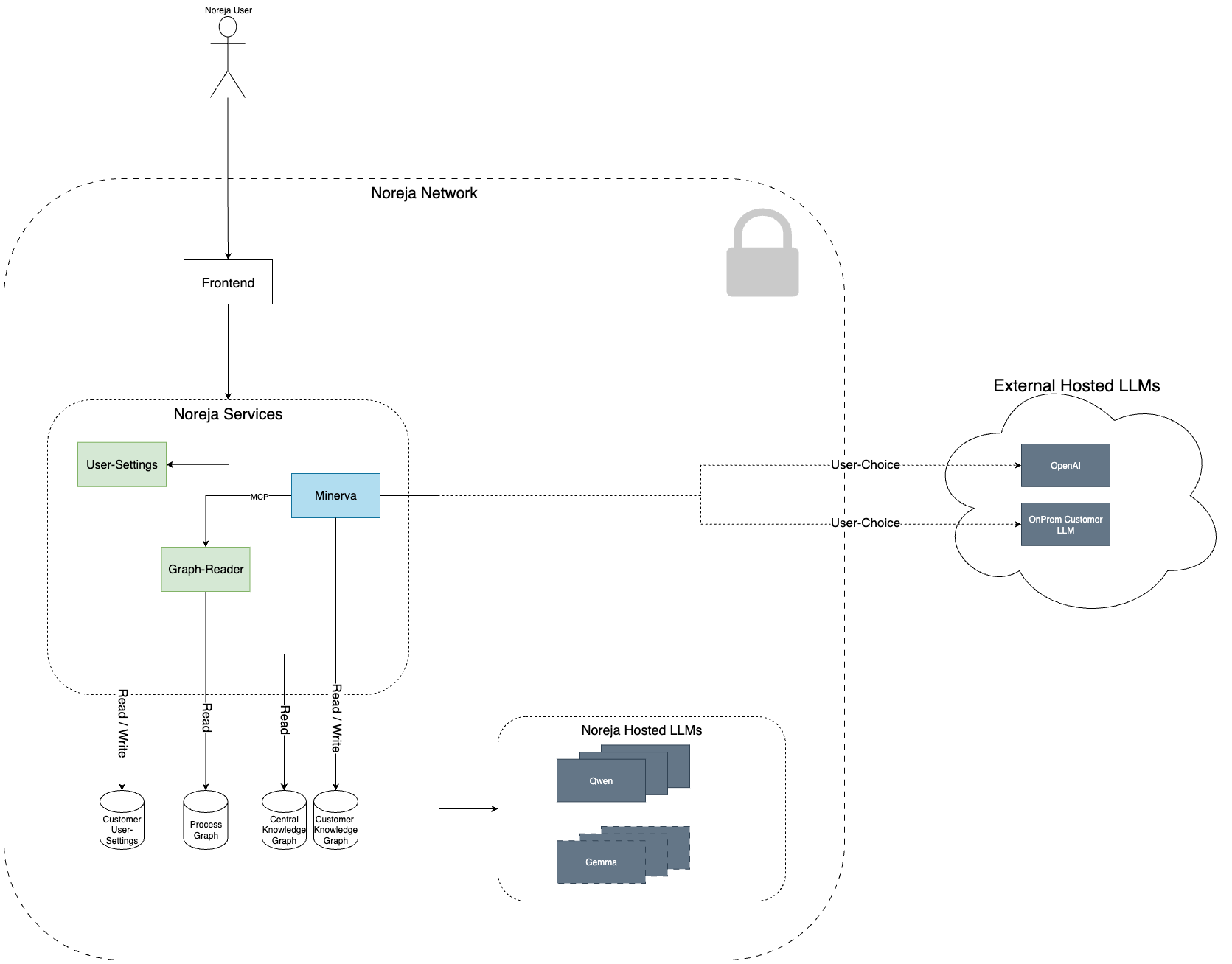
Zentrale Komponenten
Frontend:
Die Benutzeroberfläche zur Interaktion mit der Noreja-Plattform und Minerva.
Noreja Services:
Interne Dienste für Konfiguration, Datenzugriff und KI-Orchestrierung:
- User-Settings: Verwalten nutzerspezifischer Einstellungen (gesichert, kundenspezifisch gespeichert)
- Graph-Reader: Greift auf Prozess-, zentrale und kundenindividuelle Wissensgraphen zu
- Minerva: Der zentrale KI-Orchestrierungsdienst, der alle Komponenten anspricht und analysiert, wie Daten für deine Anfrage verarbeitet werden
Source Graphs:
Minerva greift auf drei Arten von Graphen zu:
- Process Graph: Prozessdaten
- Central Knowledge Graph: Geteiltes Domänenwissen
- Customer Knowledge Graph: Kontextspezifische Informationen deines Unternehmens
Modell-Integration (LLM-Schicht):
Je nach deinen Präferenzen kann Minerva mit verschiedenen Large Language Models (LLMs) verbunden werden:
- Noreja-gehostete LLMs: z. B. Qwen, Gemma
- Externe LLMs: z. B. OpenAI oder ein eigenes On-Prem-Modell
Datenschutz und Sicherheit
Deine Daten verlassen das Noreja-Netzwerk niemals, es sei denn, du hast dies explizit konfiguriert. Alle KI-Antworten basieren auf Zugriffskontrollen und Kontextinformationen deiner Umgebung. Du bestimmst, ob eine Anfrage an externe LLMs oder lokal verarbeitet wird.
Verfügbare und geplante Modelle
On-Premise
| Modellname | Anbieter | Herkunftsland |
|---|---|---|
| Qwen3 | Alibaba | China |
| Gemma | Alphabet | USA |
| Mistral | Mistral AI | France |
Cloud
| Modellname | Anbieter | Herkunftsland |
| GPT 5.2 | OpenAI | USA |
| GPT o5-mini | OpenAI | USA |
| ChatGPT 4o | OpenAI | USA |
| ChatGPT 4-turbo | OpenAI | USA |
| ChatGPT 4 | OpenAI | USA |
| ChatGPT 3.5-turbo | OpenAI | USA |
| ChatGPT o4-mini | OpenAI | USA |
Embedding-Modell im Einsatz:
multilingual-e5-embedding:
Leistungsstarkes, mehrsprachiges Modell für Vektor-Representationen
Google Gemini (Cloud)
- Verfügbarkeit: Gemini-Modelle sind ausschließlich als Cloud-Services verfügbar, ähnlich wie die Angebote von OpenAI.
- Open-Source-Alternativen: Zusätzlich zu Gemini stellt Google auch Open-Source-Modelle bereit, die wir für den On-Premise- oder hybriden Einsatz evaluieren können.
- Überlegungen: Aufgrund von Anforderungen an Datenresidenz, Latenz und Kosten wird Gemini nur für ausgewählte Anwendungsfälle in Betracht gezogen, bei denen eine cloudbasierte Inferenz akzeptabel ist.
Geplante Modelle für zukünftige Nutzung
- Embedding-Modell (geplant):
Qwen3-Embedding:8boder ein vergleichbares Modell
Ein großskaliges Embedding-Modell mit verbesserter semantischer Genauigkeit – insbesondere in domänenspezifischen Kontexten. - Re-Ranking-Modell (geplant):
Qwen3-ReRanker:8boder ein vergleichbares Modell
Wird verwendet, um semantische Suchergebnisse neu zu bewerten und die Relevanz sowie kontextuelle Präzision nach dem initialen Embedding-basierten Abruf zu erhöhen.
Integrationsanforderungen für Modelle
Inference (Antwortgenerierung)
Zur Integration eines eigenen Inference-Modells sind folgende Fähigkeiten notwendig:
- Chain-of-Thought Reasoning: Unterstützung für schrittweises, transparentes Denken
- Strukturierter Output: Fähigkeit, strukturierte Formate wie JSON oder vordefinierte Schemata auszugeben
- Tool-Calling-Fähigkeit: Unterstützung für den Aufruf externer Tools/Dienste
- MCP-Kompatibilität: Kompatibel mit unserem Model Control Protocol für einheitliche Ein-/Ausgaben
- Deployment-Optionen:
- On-Premise: Bereitstellung über HuggingFace (z. B. über HuggingFace Hub)
- Cloud: Integration über Spring AI für Cloud-Deployment
Embedding- & Re-Ranker-Modelle
Technische Anforderungen zur Integration:
- Maximaler VRAM-Bedarf: 7 GB
- Kontextfenster: Mindestens 1.000 Tokens
- Sprachen: Unterstützung von Deutsch und Englisch
- Tokenizer-Kompatibilität: Idealerweise identisch mit dem des Inference-Modells (z. B. Qwen + Qwen)
LoRA-Support (Low-Rank Adapters)
Low-Rank Adapters (LoRAs) können trainiert und in On-Premise-Modelle integriert werden, um das Modellverhalten gezielt anzupassen und die Qualität der generierten Antworten zu verbessern.
- Zweck: LoRAs ermöglichen eine leichtgewichtige Modellanpassung und machen es möglich, domänenspezifisches Wissen zu integrieren, ohne das gesamte Modell neu trainieren zu müssen.
Einsatzstatus: Aktuell sind noch keine LoRAs produktiv im Einsatz. Wir entwickeln jedoch aktiv LoRA-Komponenten für ausgewählte Teile des Workflows.
Auswirkung: On-Premise-Modelle können langfristig bessere Ergebnisse liefern als Cloud-Modelle – insbesondere in Bereichen, in denen spezialisiertes Fachwissen entscheidend ist.
Begründung: Die Anwendungsfälle unseres KI-Systems sind stark domänenspezifisch. Um dem gerecht zu werden, verfeinern wir gezielt bestimmte Modellschichten mithilfe von LoRAs, um Genauigkeit, Kontextverständnis und Relevanz zu steigern
Anwendungsfälle (Use Cases)
Use Case 1: Dokumentationshilfe on Demand
Ein Nutzer hat eine Frage zu einem beliebigen Feature der Noreja-Plattform – z. B. zur Dashboard-Konfiguration, zu Filtereinstellungen oder Begriffserklärungen. Er öffnet einfach den Minerva-Chat und stellt seine Frage. Minerva ruft sofort die relevanten Abschnitte aus der Dokumentation ab, erklärt die Funktion Schritt für Schritt und verlinkt bei Bedarf zu weiterführenden Ressourcen – so ist jedes benötigte Wissen nur eine Chatnachricht entfernt.
Use Case 2: Kontextuelle Prozessanalyse
Während der Analyse eines bestimmten Prozessabschnitts im Analyzer erkennt der Nutzer einen unerwarteten Engpass. Er aktiviert Minerva direkt in dieser Ansicht und fragt: „Was passiert hier?“ Minerva analysiert die Daten, weist auf Anomalien hin (z. B. erhöhte Durchlaufzeiten) und unterstützt den Nutzer dabei, die Ursachen interaktiv zu identifizieren – alles direkt innerhalb der Analyzer-Oberfläche.
Use Case 3: Optimierungsempfehlungen
Nach Abschluss eines Prozessdurchlaufs fragt der Nutzer: „Wie können wir das beschleunigen?“ Minerva nutzt historische Leistungsdaten und Best-Practice-Muster, um gezielte Verbesserungen vorzuschlagen – z. B. durch Aufgabenverlagerung, Parallelisierung von Schritten oder Anpassung von Schwellenwerten –, abgestimmt auf das individuelle Prozessmodell und die betrieblichen Rahmenbedingungen.
Use Case 4: Kontextbasierte Prozesseinblicke
Ein Kunde hat kontextbezogene Informationen – wie Service Level Agreements, Verfügbarkeiten von Ressourcen oder externe Rahmenbedingungen – in seinen Knowledge Graph integriert. Bei einer Analyseanfrage berücksichtigt Minerva diese kontextuellen Daten automatisch und liefert eine Prozesseinschätzung, die reale Gegebenheiten widerspiegelt. So sind Empfehlungen und Anomalie-Erkennung stets auf die tatsächliche Betriebssituation abgestimmt.
EU AI Act Konformität
Im Rahmen unseres Engagements für Transparenz und Datenschutz möchten wir einen kurzen Überblick darüber geben, wie unser KI-Assistent Minerva den Anforderungen der EU-Verordnung über Künstliche Intelligenz (EU AI Act) entspricht.
Einstufung gemäß EU AI Act
Noreja ist ein Mikro-Unternehmen (weniger als 10 Mitarbeitende, Jahresumsatz unter 2 Millionen Euro). Dadurch gelten für uns vereinfachte Regelungen im Sinne des EU AI Act – mit verlängerten Fristen und reduziertem Verwaltungsaufwand. Dennoch setzen wir die grundlegenden Prinzipien der Verordnung proaktiv um.
Art der KI-Nutzung
Minerva ist als Entscheidungsunterstützungssystem innerhalb der Noreja-Plattform konzipiert. Es unterstützt Nutzer bei der Analyse komplexer Prozessdaten durch kontextbewusste Hinweise und Empfehlungen. Es trifft keine automatisierten Entscheidungen mit rechtlicher oder ähnlich weitreichender Wirkung.
Daher fällt Minerva nicht in die Kategorie "Hochrisiko-KI-Systeme" gemäß EU AI Act.
Datenverarbeitung und Nutzerkontrolle
Datenzugriff
Minerva verarbeitet ausschließlich vom Kunden bereitgestellte Daten, darunter:
- Kontextuelle Metadaten zu Prozessschritten
- Analyserelevante Datenbankinhalte
Die Art und Sensitivität der Daten hängt von der konkreten Kundeneinbindung ab.
Modellwahl und Kontrolle
Kunden haben vollständige Kontrolle über das verwendete Modell:
Auswahl zwischen Noreja-eigenen Modellen, externen Anbietern wie OpenAI oder eigenen On-Premise-LLM-Modellen.
Sämtliche Anfragen und Modellinteraktionen werden protokolliert und sind nachvollziehbar
Transparenz bei externer Verarbeitung
Wird ein externes Modell (z. B. OpenAI) gewählt, erfolgt eine Datenübertragung nur nach ausdrücklicher Konfiguration durch den Kunden außerhalb des Noreja-Netzwerks.
Kein standardmäßiger Transfer personenbezogener Daten
Persönliche Daten werden nicht automatisch an externe Anbieter übermittelt – dies geschieht nur mit ausdrücklicher Zustimmung.
Data Processing Agreement (DPA)
Wir bieten unsere Datenverarbeitung auf Basis eines transparenten Service-Modells an. Ein formelles Data Processing Agreement (DPA) wird aktuell vorbereitet und allen Kunden zur Verfügung gestellt. Es regelt unter anderem:
- Verantwortlichkeiten bei der Datenverarbeitung
- Einbindung von Subprozessoren
- Bedingungen zur Nutzung von LLMs (inkl. Drittanbietern)