
Der Ursprung des Causal Process Mining
*Der folgende Text ist ein Auszug aus einer Forschungsarbeit, die vom Gründerteam von Noreja veröffentlicht wurde.
Zusammenfassung
Die Vielzahl an Algorithmen im Forschungsfeld des Process Mining basiert auf sogenannten Directly-Follows-Beziehungen. Trotz zahlreicher Verbesserungen im letzten Jahrzehnt weisen diese Beziehungen gravierende Schwächen auf. Sobald Ereignisse mit unterschiedlichen Objekten verknüpft sind, die in einer Kardinalität von 1:N oder N:M zueinanderstehen, erzeugen Techniken, die auf Directly-Follows-Beziehungen basieren, fehlerhafte Verbindungen, Selbstschleifen und Rücksprünge. Dies liegt daran, dass die Ereignisfolge, wie sie in klassischen Event Logs beschrieben ist, sich von kausalen Zusammenhängen unterscheidet. In dieser Arbeit widmen wir uns dem Forschungsproblem, wie sich die kausale Struktur prozessbezogener Ereignisdaten abbilden lässt. Zu diesem Zweck entwickeln wir einen neuen Ansatz namens Causal Process Mining. Dieser Ansatz verzichtet auf die Verwendung flacher Event Logs und nutzt relationale Datenbanken mit Ereignisdaten als Eingabe. Konkret transformieren wir die relationalen Datenstrukturen mithilfe der Causal Process Template in das, was wir Causal Event Graph nennen. Wir evaluieren unseren Ansatz und vergleichen die Ergebnisse mit Techniken, die auf Directly-Follows-Beziehungen basieren, anhand einer Fallstudie mit einem europäischen Lebensmittelproduzenten. Unsere Ergebnisse zeigen die Vorteile, die sich durch die Anreicherung des Process Minings mit zusätzlichem Domänenwissen ergeben.
Überblick und Hintergrund
Process Mining (PM) ist ein Forschungsfeld, das sich auf die Entwicklung automatisierter Analysetechniken konzentriert, die mithilfe von Ereignisdaten Einblicke in Geschäftsprozesse ermöglichen. Im letzten Jahrzehnt wurde erheblicher Aufwand betrieben, um Algorithmen zur automatisierten Prozesserkennung zu verbessern. Bedeutende Fortschritte beinhalten den Inductive Miner, den Evolutionary Tree Miner oder den Split Miner. Diese Algorithmen unterscheiden sich im Hinblick auf die Ausgewogenheit zwischen Fitness, Einfachheit, Generalisierung und Präzision, um besser mit unterschiedlichen Event Log-Charakteristiken oder Anwendungsfällen umgehen zu können. Gemeinsam ist ihnen jedoch, dass sie auf Event Logs als Eingabe und Directly-Follows-Beziehungen zur Modellerzeugung setzen.
Obwohl die meisten PM-Techniken auf Event Logs und Directly-Follows-Beziehungen aufbauen, zeigen sie erhebliche Schwächen. Wenn Ereignisse mit verschiedenen Objekten verknüpft sind, die zueinander in einer 1:N- oder N:M-Beziehung stehen, erzeugen solche Techniken fehlerhafte Verbindungen, Selbstschleifen und Rücksprünge. Die Unfähigkeit, diese Kardinalitäten angemessen zu behandeln, führt zu einem Repräsentationsbias, der insbesondere bei der Modellierung logistischer Prozesse zu Problemen führt – hier lassen sich interagierende Objekte nicht mit einem einzelnen Fall-Identifier nachverfolgen.
Aktuelle Arbeiten zu artefaktbezogenem oder objektzentriertem PM sowie Ansätze, die relationale Datenbanken oder multidimensionale Ereignisdaten berücksichtigen, adressieren dieses Problem, indem sie ein einzelnes Ereignis mit mehreren Objekten verknüpfen. Allerdings nutzen sie kein kausales Domänenwissen, wie es beispielsweise in Fremdschlüsselbeziehungen von Datenbanken mit Ereignisdaten sichtbar wird. Dies stellt ein grundlegendes Problem dar, da sich kausale Zusammenhänge nicht allein durch Beobachtung rekonstruieren lassen. Infolgedessen erzeugen auf Directly-Follows Graphs (DFGs) basierende Techniken Verbindungen, die nicht kausal sind, und führen zu übermäßig komplexen Modellen.
In dieser Arbeit adressieren wir das Problem der Darstellung der kausalen Struktur prozessbezogener Ereignisdaten. Dafür entwickeln wir einen neuen Ansatz namens Causal Process Mining (CPM). Dieser verzichtet auf flache Event Logs und nutzt relationale Datenbanken mit Ereignisdaten sowie kausales Wissen als Eingabe. Genauer gesagt transformieren wir die relationalen Datenstrukturen basierend auf der Causal Process Template (CPT) in das, was wir Causal Event Graph (CEG) nennen. Diese CEGs können in einer Graphdatenbank gespeichert und zu Modellen aggregiert werden, die wir Aggregated Causal Event Graphs (ACEGs) nennen. CPM nutzt diese Strukturen und bietet verschiedene Operationen, um den Prozess aus unterschiedlichen Perspektiven und auf verschiedenen Aggregationsebenen zu analysieren.
Unterschiede zwischen Directly-Follows- und Causal Graphs
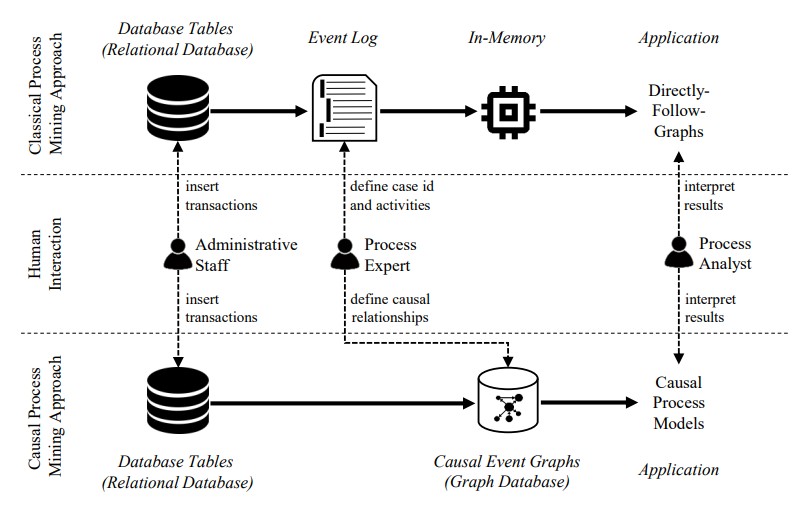
Bevor wir die Details unseres Ansatzes vorstellen, möchten wir ihn den klassischen PM-Ansätzen gegenüberstellen, die auf DFGs und Event Logs basieren. Die folgende Abbildung zeigt einen Überblick über die einzelnen Schritte beider Ansätze und darüber, wo Menschen eingebunden sind.
Klassische Ansätze (obere Spur in der Abbildung) bestehen aus vier Schritten. Zuerst werden während der Ausführung eines Geschäftsprozesses Transaktionen in eine Datenbank eingetragen. Diese Transaktionen werden in Tabellen relationaler Datenbanken gespeichert, die durch Fremdschlüsselbeziehungen mit unterschiedlichen Kardinalitäten miteinander verbunden sind. Zweitens definiert ein Prozessexperte für die Erstellung des Event Logs den notwendigen Case-Identifier, spezifiziert die Prozessaktivitäten sowie dazugehörige Eigenschaften wie Ressourcen, Zeitstempel oder andere Geschäftsobjekte. Auf Basis dieser Informationen wird ein flaches Event Log extrahiert. Drittens wird dieses Event Log in den Arbeitsspeicher geladen und ein DFG daraus berechnet. Viertens kann ein Prozessanalyst die Visualisierung am Bildschirm interpretieren.
Unser CPM-Ansatz (untere Spur in der Abbildung) extrahiert die relevanten Daten ebenfalls aus einer relationalen Datenbank, was mit dem klassischen Vorgehen übereinstimmt. Der zweite Schritt unterscheidet sich jedoch grundlegend: Die Extraktion eines separaten Event Logs entfällt. Stattdessen übertragen wir die relationalen Datenbankstrukturen direkt in CEGs und speichern sie in einer Graphdatenbank. Auf diese Weise vermeiden wir das Flattening der Daten und erhalten Kardinalitäten sowie kausale Beziehungen zwischen den Datenobjekten. Die benutzerseitige Anwendung muss dann lediglich die CEGs in einer auf den Anwendungsfall zugeschnittenen Weise visualisieren.
Aus technischer Sicht verlagert sich dadurch die Berechnung von der Anwendungsebene auf die Datenbankebene. Dies bringt Wiederverwendbarkeit, da verschiedene Frontend-Anwendungen unabhängig auf die Daten zugreifen können, sowie Flexibilität, da die CEGs nicht an einen vordefinierten Case-Identifier gebunden sind. In den folgenden Abschnitten stellen wir unseren Ansatz formell vor.
Definitionen und Anforderungen an CPM
Den vollständigen Artikel finden Sie hier: https://arxiv.org/pdf/2202.08314
Fazit
Die aktuelle Forschung im Bereich des Process Mining hat viel Aufwand in die Entwicklung und Verbesserung automatisierter Algorithmen zur Prozesserkennung investiert. Das Ergebnis sind Algorithmen mit hoher Präzision und Recall – aber auch mit komplexen, unübersichtlichen („Spaghetti“) Modellen.
In dieser Arbeit haben wir einen neuartigen Ansatz für Causal Process Mining (CPM) entwickelt, der auf Wissen über kausale Zusammenhänge basiert. Wir haben den Noreja-Ansatz vorgestellt, der das in einem CPT definierte Kausalwissen nutzt, um einen CEG zu erzeugen. Anschließend werden verschiedene Aggregationsebenen dieser CEGs als ACEG aufgebaut. Der Noreja-Ansatz nutzt diese Strukturen, um eine Vielzahl von Operationen zur Analyse von Prozessen auf unterschiedlichen Aggregationsebenen und aus verschiedenen Perspektiven anzubieten.
Unsere Evaluation belegt die Vorteile von CPM und die Berücksichtigung kausalen Wissens bei der Prozesserkennung. Die Ergebnisse zeigen, dass der vorgestellte Noreja-Ansatz weniger komplexe Prozessmodelle erzeugt als die Vergleichsansätze. Ein wesentlicher Grund hierfür ist, dass der Noreja-Ansatz nicht mit den Problemen umgeht, die durch 1:N-, N:1- und N:M-Beziehungen im Datenbankschema entstehen. Ein zweiter Grund für die geringere Komplexität liegt in der Art und Weise, wie der Noreja-Ansatz Situationen wie nachträgliche Updates eines Prozessinstanz behandelt. Anstatt zusätzliche Verbindungen zu erzeugen, die das Prozessmodell verkomplizieren, führen solche Situationen lediglich zu zeitlichen Verletzungen.