
The Origin of Causal Process Mining
* The following text is an extraction out of a research paper published by the Noreja founders team
Abstract
The plethora of algorithms in the research field of process mining builds on directly-follows relations. Even though various improvements have been made in the last decade, there are serious weaknesses of these relationships. Once events associated with different objects that relate with a cardinality of 1:N and N:M to each other, techniques based on directly-follows relations produce spurious relations, self-loops, and back-jumps. This is due to the fact that event sequence as described in classical event logs differs from event causation. In this paper, we address the research problem of representing the causal structure of process-related event data. To this end, we develop a new approach called Causal Process Mining. This approach renounces the use of flat event logs and considers relational databases of event data as an input. More specifically, we transform the relational data structures based on the Causal Process Template into what we call Causal Event Graph. We evaluate our approach and compare its outputs with techniques based on directly-follows relations in a case study with an European food production company. Our results demonstrate the benefits for enriching process mining with additional knowledge from the domain.
Overview and Background
Process Mining (PM) is a research field focusing on the development of automatic analysis techniques that provide insights into business processes based on event data. Over the last decade, PM research has spent considerable efforts on improving algorithms for automatic process discovery. Notable advancements of recent algorithms include the inductive miner, the evolutionary tree miner, or the split miner. These algorithms differ in their balance between fitness, simplicity, generalization, and precision in order to better cope with different event log characteristics or use cases, but they have in common that they build on event logs as input and directly-follows relations for generating models. Even though most PM techniques build on event logs and directly-follows relations, they exhibit some serious weaknesses. Once events associated with different objects that relate with a cardinality of 1:N and N:M to each other, techniques based on directly-follows relations produce spurious relations, selfloops, and back-jumps. The incapability to handle such cardinality constitutes a representational bias that causes problems for appropriately representing, a.o., logistic processes. Here, interacting objects cannot be traced using a single case identifier. Recent works on artifact-related PM or object-centric PM as well as approaches that consider relational databases or multi-dimensional event data address the problem by associating a single event with one or more objects. However, they do not exploit causal domain knowledge such as visible in the foreign key relationships of the databases storing event data. This is a fundamental problem, because it is not possible to reconstruct causal relationships from observation of behavior alone. As a consequence, techniques based on Directly-Follows Graphs (DFGs) produce connections that are not causal, yielding overly complex models. In this paper, we address the problem of representing the causal structure of process-related event data. To this end, we develop a new approach called Causal Process Mining (CPM). This approach renounces the use of flat event logs and considers relational databases of event data as well as causal knowledge as an input. More specifically, we transform the relational data structures based on the Causal Process Template (CPT) into what we call Causal Event Graph (CEG). In turn, these CEGs can be stored in a graph database and they can be aggregated to models that we call Aggregated Causal Event Graphs (ACEGs). CPM exploits these structures and offers multiple operations to investigate the process from various perspectives and at different levels of aggregation.
Differences Between Directly-Follows and Causal Graphs
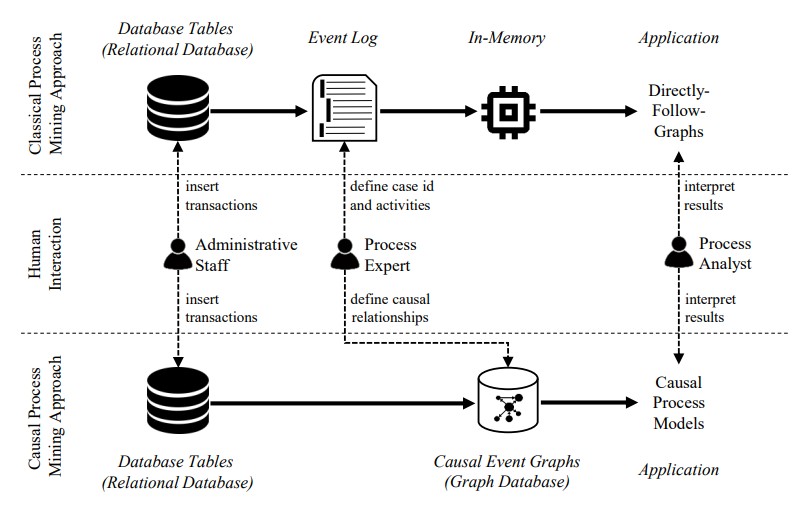
Before going into the details of our approach, we want to juxtapose it with classical PM approaches based on DFGs and event logs. The figure below gives an overview of the different steps of each approach and where humans are involved. Classical approaches (top lane in figure) build on four steps. First, transactions are inserted into a database during the execution of a business process. Those transactions are persisted inside tables of relational databases, which themselves are connected by foreign-key relations with different cardinalities. Second, in preparation for creating the event log, a process expert defines the obligatory case identifier, specifies the process activities and related properties, such as resources, timestamps, or other business objects. Based on this information, a flattened event log is extracted. Third, the event log is loaded into memory where the DFG is calculated as an output. Fourth, a process analyst can interpret the visualization on the screen. Our CPM approach (bottom lane in figure) extracts the relevant data from a relational database, which matches the classical approach. However, the second step has fundamental differences, because the extraction of a dedicated event log is skipped. Instead, we directly transfer the relational database structures into CEGs and store them in a graph database. In this way, we avoid flattening the data, such that we keep cardinalities and causal relationships between data objects. The user-facing application then only has to visualize the CEGs in a use-case specific manner. From a technical perspective, this shifts computation from the application layer to the database layer. We obtain reusability as different user-facing applications can query the data independently, and flexibility as the CEG is not bound to a predefined case identifier. In the subsequent sections, we present our approach from formal perspective.
Definitions and Requirements for CPM
Read the full paper here: https://arxiv.org/pdf/2202.08314
Conclusion
Recent PM research has spent considerable effort on developing and improving automatic process discovery algorithms. The outcome of these efforts are algorithms with high precision and recall but also complex Spaghetti models. In this paper, we developed a novel approach to CPM that is based on knowledge about causal relations. We presented the Noreja Approach that utilizes the causal knowledge defined in a CPT to create a CEG. Subsequently, different aggregation levels of these CEGs are created in form of ACEG. The Noreja approach then exploits these structures to offer multiple operations to analyze the process on different levels of aggregation and from various perspectives. Our evaluation demonstrates the benefits of CPM and the consideration of causal knowledge during process discovery. The evaluation shows that the presented Noreja Approach creates less complex process models than the compared approaches. One of the main reasons for this is the fact that the Noreja Approach does not struggle with the problem that is inherent with the 1:N, N:1, and N:M relations of database schema. A second reason for less complex models is attributable to how the Noreja Approach handles situations like later updates of a process instance. Instead of resulting in additional relationships, which complicate the process model, such situations result in temporal violations.