
Minerva Architecture
General
In this article, you will find a clear overview of Minerva’s system architecture, an outline of the AI models we support (including on-premise and third-party options) and the requirements for integrating your own model, a step-by-step depiction of our internal data flow, illustrative use cases demonstrating how Minerva can enhance process mining workflows, and a concise compliance summary under the EU AI Act.
Architecture
The diagram below outlines the high-level architecture of our AI assistant Minerva, which is seamlessly integrated into the Noreja platform. This overview is designed to help you understand how data flows through our system and how our AI features interact with your data — always respecting your preferences and data privacy.
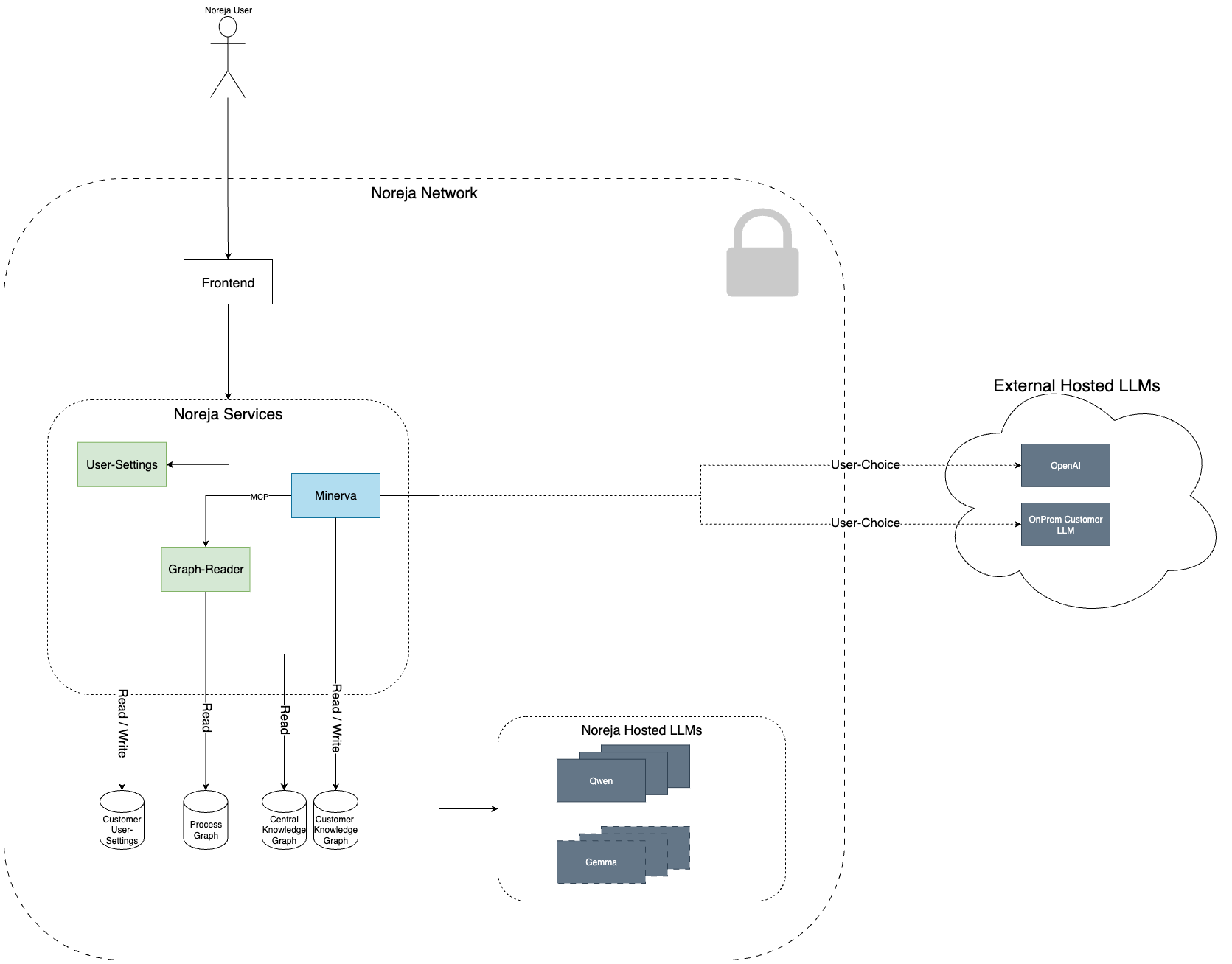
Key Components
Frontend
The user interface through which you interact with the Noreja platform, including the Minerva AI assistant.
Noreja Services
A set of internal services responsible for handling configuration, data access, and AI orchestration:
- User-Settings manages individual preferences, which are stored and read from a secure customer-specific storage.
- Graph-Reader accesses the underlying process, central, and customer-specific knowledge graphs.
- Minerva, the core AI orchestration service, communicates with all components and determines how data is retrieved and analyzed for your queries.
Source Graphs
Minerva accesses three types of graphs:
- Process Graph – representing your process data.
- Central Knowledge Graph – housing shared domain knowledge.
- Customer Knowledge Graph – containing contextual information specific to your organization.
Model Integration (LLM Layer)
Depending on your preferences, Minerva can connect to different Large Language Models (LLMs):
- Noreja Hosted LLMs such as Qwen and Gemma.
- External LLMs, either via OpenAI or your own On-Prem Customer LLM instance, allowing for full control and local deployment.
Privacy and Data Security
Your data never leaves the Noreja Network unless explicitly configured by you. All AI responses are generated based on data access rules and contextual information defined in your environment. You stay in full control of whether queries are sent to externally hosted LLMs or handled locally.
Available and Planned Models
On Premise
| Model Name | Distributor | Country of Origin |
|---|---|---|
| Qwen3 | Alibaba | China |
| Gemma | Alphabet | USA |
| Mistral | Mistral AI | France |
Cloud
| Model Name | Distributor | Country of Origin |
|---|---|---|
| GPT 5.2 | OpenAI | USA |
| GPT o5-mini | OpenAI | USA |
| GPT 4o | OpenAI | USA |
| GPT 4-turbo | OpenAI | USA |
| GPT 4 | OpenAI | USA |
| GPT 3.5-turbo | OpenAI | USA |
| GPT o4-mini | OpenAI | USA |
Embedding Model in Use
multilingual-e5-embedding
A performant, multilingual embedding model used for our default vector representation across supported languages.
Google Gemini (Cloud Integration)
- Availability: Gemini models are available exclusively as cloud services, similar to OpenAI's offerings.
- Open-Source Alternatives: In addition to Gemini, Google provides open-source models that we may evaluate for on-premise or hybrid deployment scenarios.
- Considerations: Due to data residency, latency, and cost considerations, Gemini may be evaluated for selective use cases where cloud-based inference is acceptable.
Models Planned for Future Use
- Embedding Model (Planned):
Qwen3-Embedding:8bor similar
A large-scale embedding model offering improved semantic accuracy, particularly in domain-specific contexts. - Re-Ranking Model (Planned):
Qwen3-ReRanker:8bor similar
Used to re-rank semantic search results, increasing response relevance and contextual precision after the initial embedding-based retrieval step.
Model Integration Requirements
Inference (Answer Generation)
To integrate a custom inference model into our platform, the following capabilities are required:
- Chain-of-Thought Reasoning: The model should support step-by-step reasoning to ensure transparent and structured responses.
- Structured Output Support: The model must be able to produce well-structured output formats, such as JSON or predefined schemas.
- Tool Calling Capabilities: It should support tool or function calling to enable dynamic interaction with external services or data sources.
- MCP Compatibility: The model must be compatible with our Model Control Protocol (MCP) for unified request and response handling.
- Deployment Options:
- On-Premise: The model must be available via HuggingFace (e.g., hosted or downloadable through the HuggingFace Hub).
- Cloud: Integration with Spring AI must be supported for seamless deployment in cloud environments.
Embedding & Re-Ranker Models
To integrate custom models for embeddings or re-ranking tasks, please ensure the following technical criteria are met:
- Memory Requirements: The model must run within a maximum of 7GB VRAM to ensure efficient deployment across environments.
- Context Window: A minimum context window of 1,000 tokens is required to maintain effectiveness across varied prompts.
- Language Support: The model must support both German and English out of the box.
- Tokenizer Alignment: Ideally, the tokenizer should match that of the inference model (e.g., Qwen + Qwen or OpenAI + OpenAI) to avoid inconsistencies during embedding or downstream inference tasks.
LoRA Support (Low-Rank Adapters)
Low-Rank Adapters (LoRAs) can be trained and integrated into on-premise models to fine-tune behavior and enhance the quality of generated responses.
- Purpose: LoRAs allow for lightweight model adaptation, making it possible to inject domain-specific knowledge without retraining the full model.
- Deployment Status: Currently, no LoRAs are deployed. However, we are actively developing LoRA components for selected parts of the workflow.
- Impact: On-premise models may deliver better results than cloud-hosted models over time, especially in areas where specialized domain knowledge is critical.
- Rationale: The underlying use cases of our AI system are highly domain-specific. To address this, we will fine-tune certain model layers using LoRAs to improve accuracy, contextuality, and relevance.
Use Cases
Use Case 1: On-Demand Documentation Assistant
A user encounters a question about any feature within the Noreja platform—be it dashboard configuration, filter settings, or terminology. They simply open the Minerva chat and ask their question. Instantly, Minerva retrieves the relevant sections of our documentation, explains the functionality step-by-step, and even links to deeper resources, ensuring that every piece of knowledge is just one chat message away.
Use Case 2: Contextual Process Analysis
While exploring a specific process view in the Analyzer, the user notices an unexpected bottleneck. They invoke Minerva directly within that view and say, “What’s happening here?” Minerva analyzes the data, points out anomalies (e.g., spikes in throughput time), and collaborates interactively to help the user drill down into root causes—all without leaving the Analyzer interface.
Use Case 3: Optimization Recommendations
After reviewing a completed process run, the user asks Minerva, “How can we make this faster?” Leveraging historical performance metrics and best-practice patterns, Minerva proposes targeted improvements—such as reassigning tasks, parallelizing steps, or adjusting thresholds—that are tailored to the customer’s process model and operational constraints.
Use Case 4: Context-Enriched Process Insights
A customer has uploaded/added custom contextual data—like service-level agreements, resource availability, or other external information—into their knowledge graph. When the user requests an analysis, Minerva seamlessly incorporates these context layers, delivering a process evaluation that reflects real-world conditions. This ensures that recommendations and anomaly detection are grounded in the customer’s unique operational environment.
EU AI Act Compliance
As part of our commitment to transparency and data protection, we would like to provide a brief overview of how our AI assistant Minerva aligns with the requirements of the EU AI Act.
Classification under the EU AI Act
Noreja qualifies as a microenterprise (fewer than 10 employees, annual turnover below €2 million). Under the EU AI Act, this grants us a simplified compliance pathway, with extended timelines and reduced administrative burden. Nevertheless, we strive to implement the core principles of the regulation proactively.
Nature of the AI Use
Minerva is designed as a decision-support system within the Noreja platform. It assists users in navigating complex process data by offering context-aware suggestions and insights. It does not make automated decisions with legal or similarly significant effects.
As such, the system does not fall under the "high-risk AI system" category of the EU AI Act.
Data Handling and User Control
Data Access
Minerva processes customer-provided data, including:
- contextual metadata about process steps
- database content shared for analysis
The specific type and sensitivity of the data depend on what the customer chooses to integrate.
Model Selection & Control
Customers have full control over the model used for their queries:
You may choose between Noreja-hosted models, external providers like OpenAI, or even connect your own on-premise LLM.
All requests and model interactions are logged and auditable.
External Processing Transparency
If you choose an external model (e.g. OpenAI), data will be sent outside the Noreja network. This only happens based on your explicit configuration.
No Default Personal Data Transfer
We do not transfer personal data to external AI providers unless explicitly enabled and permitted by you.
Data Processing Agreement (DPA)
We currently offer data processing under a transparent service structure. A formal Data Processing Agreement (DPA) is being prepared and will be made available to all customers. This DPA will clarify:
- data handling responsibilities
- subprocessor involvement
- provisions for using LLMs (including third-party providers)